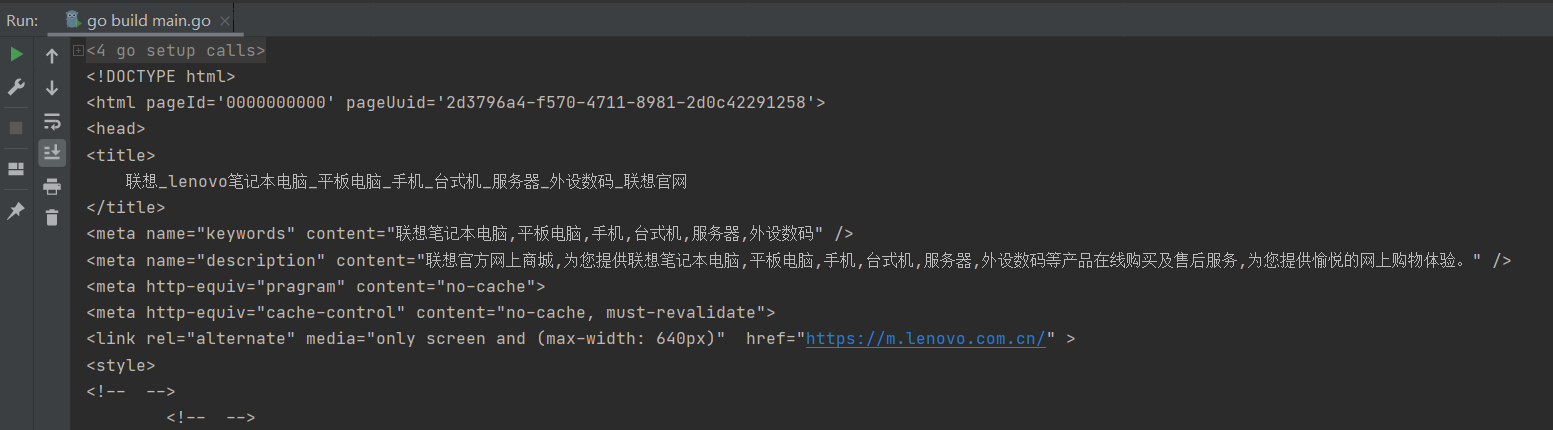
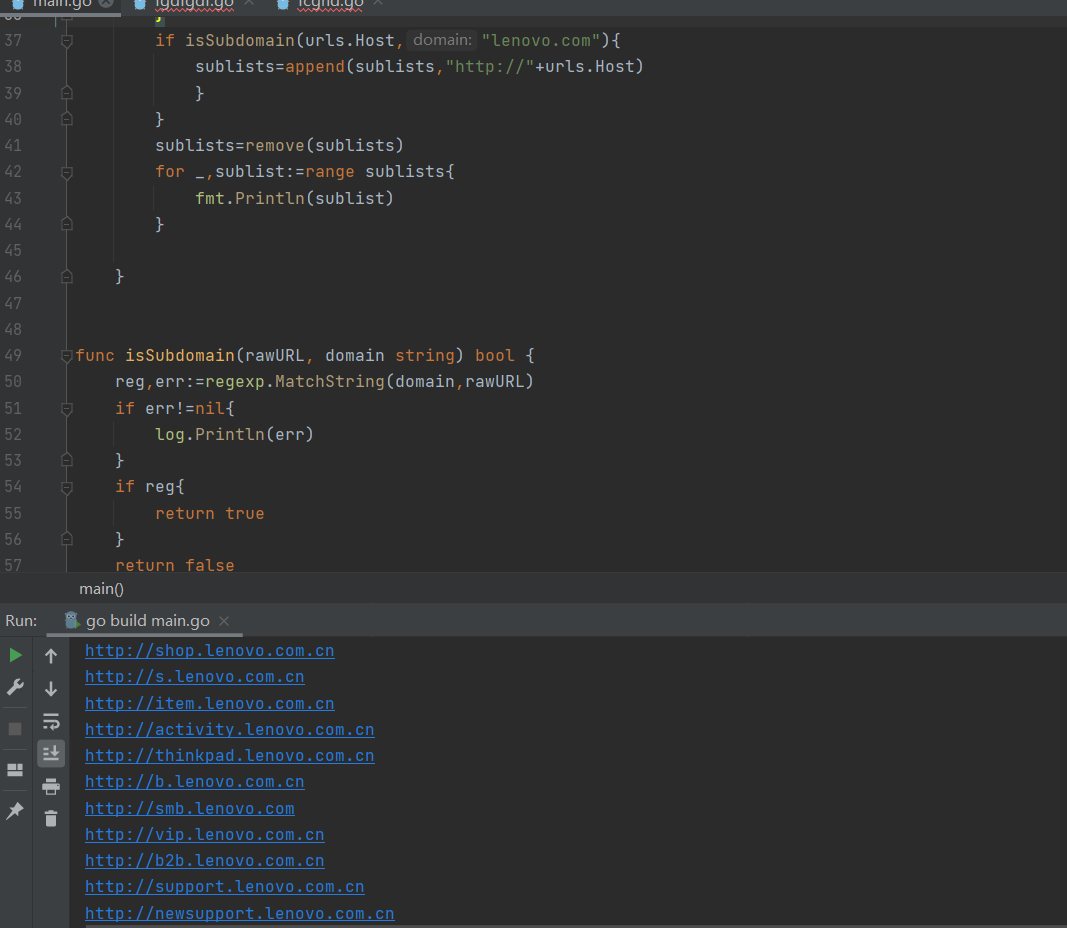
funcisSubdomain(rawURL, domain string)bool { reg,err:=regexp.MatchString(domain,rawURL) if err!=nil{ log.Println(err) } if reg{ returntrue } returnfalse }
remove
去重这里参考了网上数组切片去重的方式。
1 2 3 4 5 6 7 8 9 10 11
funcremove(languages []string) []string { result := make([]string, 0, len(languages)) temp := map[string]struct{}{} for _, item := range languages { if _, ok := temp[item]; !ok { temp[item] = struct{}{} result = append(result, item) } } return result }
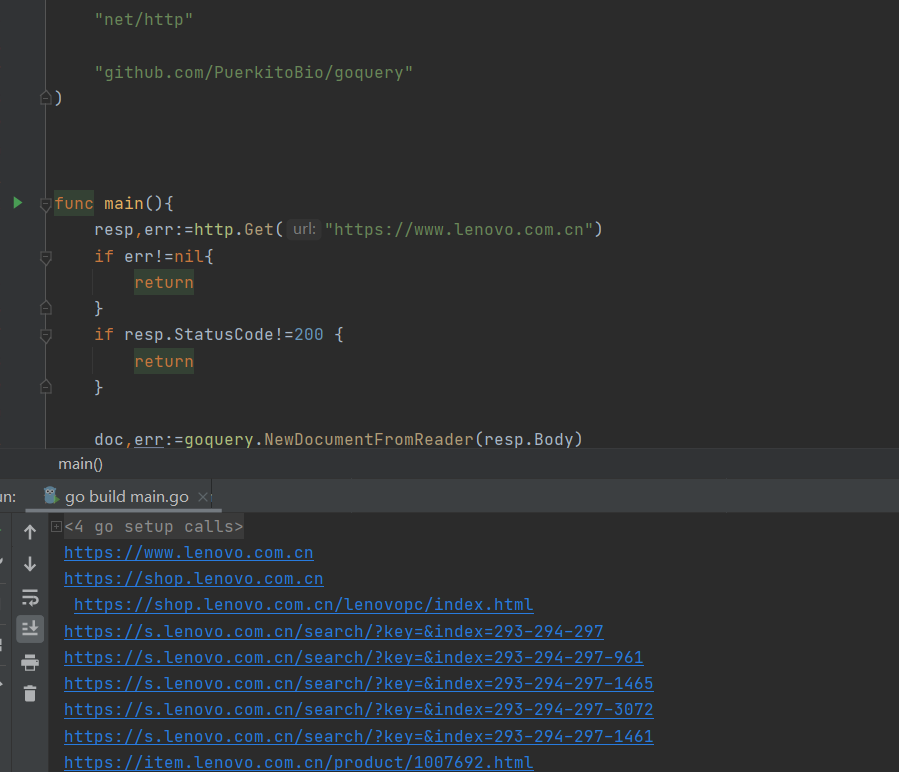
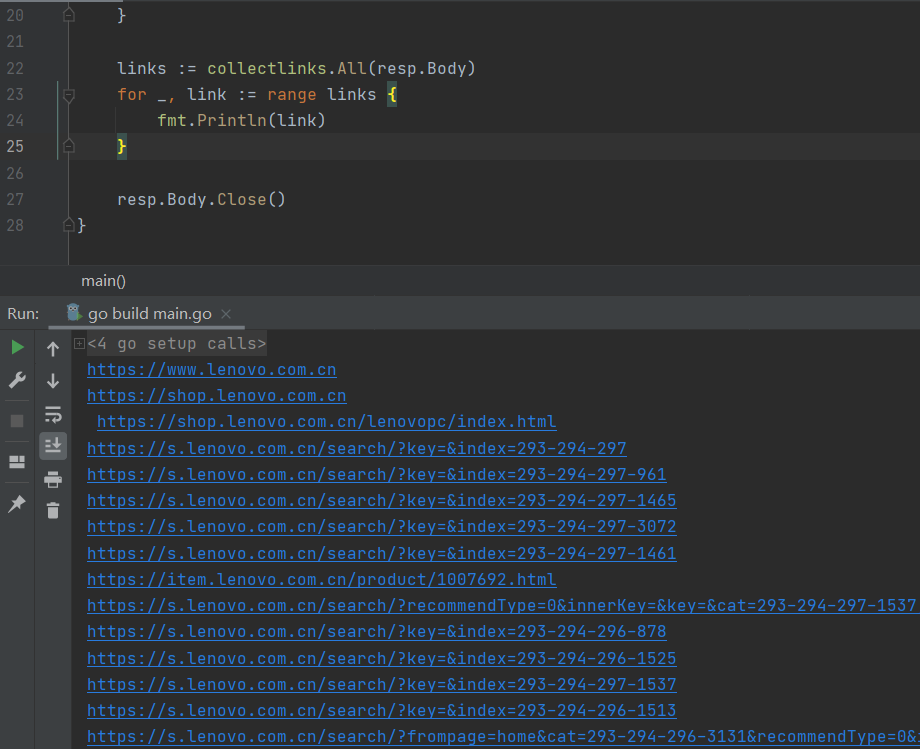
for _, link := range links { urls,err:=url.Parse(link) if err!=nil { log.Println(err) continue } if isSubdomain(urls.Host,"lenovo.com"){ sublists=append(sublists,"http://"+urls.Host) } } sublists=remove(sublists) for _,sublist:=range sublists{ fmt.Println(sublist) }
}
funcisSubdomain(rawURL, domain string)bool { reg,err:=regexp.MatchString(domain,rawURL) if err!=nil{ log.Println(err) } if reg{ returntrue } returnfalse }
funcremove(languages []string) []string { result := make([]string, 0, len(languages)) temp := map[string]struct{}{} for _, item := range languages { if _, ok := temp[item]; !ok { temp[item] = struct{}{} result = append(result, item) } } return result }
for _, link := range links { urls,err:=url.Parse(link) iferr!=nil { log.Println(err) continue } if isSubdomain(urls.Host,"lenovo.com"){ sublists=append(sublists,"http://"+urls.Host) } } sublists=remove(sublists)
return sublists }
然后在主函数中进行循环爬取:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
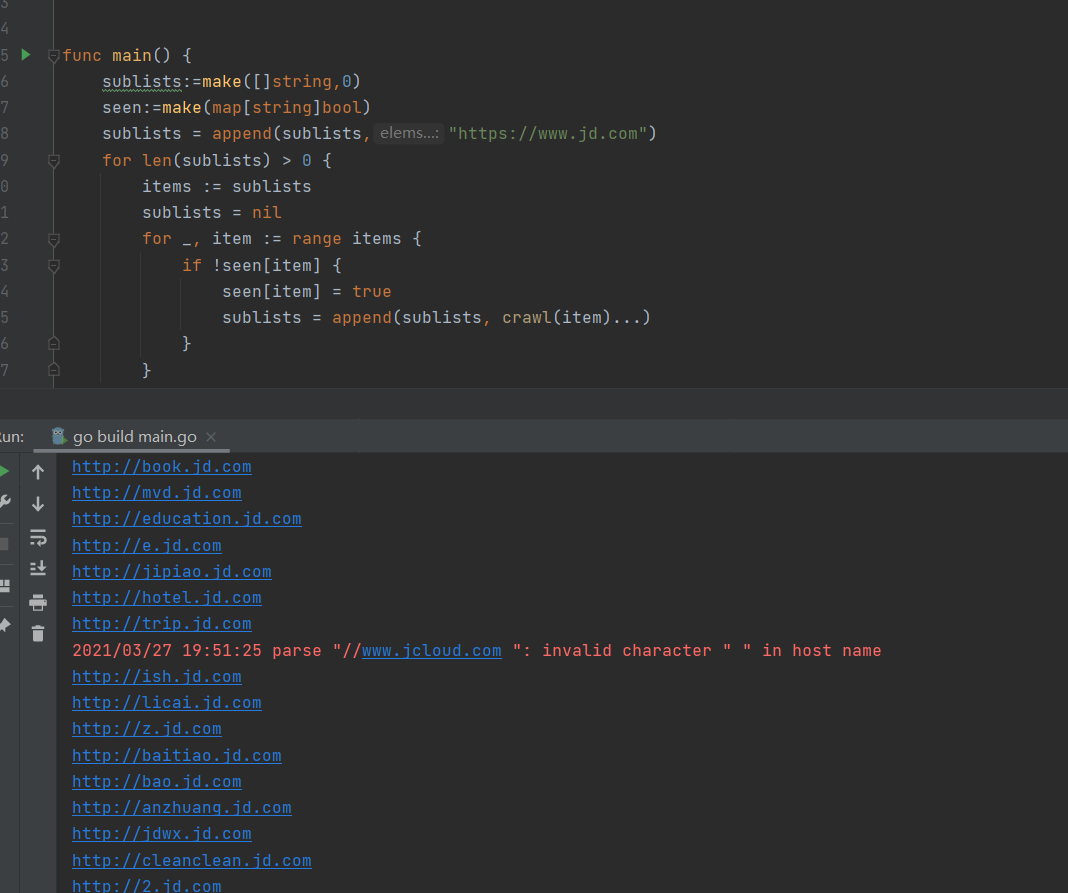
funcmain() { sublists:=make([]string,0) seen:=make(map[string]bool) sublists = append(sublists,"http://www.lenovo.com.cn") for len(sublists) > 0 { items := sublists sublists = nil for _, item := range items { if !seen[item] { seen[item] = true sublists = append(sublists, crawl(item)...) } } } }
这里爬了下jd,效果还是挺明显的:
这里在爬取过程会遇到一个异常:dial tcp: lookup help.en.jd.com: no such host,
for _, link := range links { urls,err:=url.Parse(link) if err!=nil { log.Println(err) continue } if isSubdomain(urls.Host,"jd.com"){ sublists=append(sublists,"http://"+urls.Host) } } sublists=remove(sublists)
funcisSubdomain(rawURL, domain string)bool { reg,err:=regexp.MatchString(domain,rawURL) if err!=nil{ log.Println(err) } if reg{ returntrue } returnfalse }
funcremove(languages []string) []string { result := make([]string, 0, len(languages)) temp := map[string]struct{}{} for _, item := range languages { if _, ok := temp[item]; !ok { temp[item] = struct{}{} result = append(result, item) } } return result }
for list := range worklist { for _, link := range list { if !seen[link] { seen[link] = true gofunc(link string) { worklist <- crawl(link) }(link) } } } }